
This article previously appeared in the Process Mining News. Sign up here to receive more articles about the practical application of process mining.
One of the first things that you learn in the process mining methodology is how to filter out incomplete cases to get an overview about what the regular end-to-end process looks like.
Incomplete cases are process instances that have not finished yet. They are somewhere “in the middle” of the process. You typically remove such incomplete cases, for example, when you analyze the average case duration because the case duration of incomplete cases is misleading. The time between the first and the last event in an incomplete case can appear to be very fast, but in fact only a fraction of the process has taken place so far: If you would have waited a few more days, or weeks, then more activities would likely have taken place.
But what if you are exactly interested in those incomplete cases?
For example, you may want to know how long they have been open, how long nothing happened since the last activity or status change, and which statuses accumulate the most and most severe open cases without any action afterwards? These may be cases, where the customerunnoticed by the companyhas been already waiting for a long time and is about to be disappointed.
In this article, we show you how you can include the perspective of open cases in your process mining analysis. We provide detailed step-by-step instructions (download Disco if you have not done so yet) to follow along.
1. Apply filter to focus on incomplete cases
As a first step, we need to filter our data set to focus on the incomplete cases. One typical way to do that is to use the Endpoints filter, where you can first select the expected endpoints, and then invert the selection (by pressing the half-filled circle next to the search icon in the upper right corner of the filter settings).
Another way to filter incomplete cases is to focus on whether neither of the expected milestones in the process has been reached using the Forbidden mode in the Attribute filter. For example, in a customer refund process, these milestones may be activities such as Canceled, Order completed, and Payment issued, because they indicate that the refund order is not open anymore for the customer (see below - click on the screenshot to see a larger version).
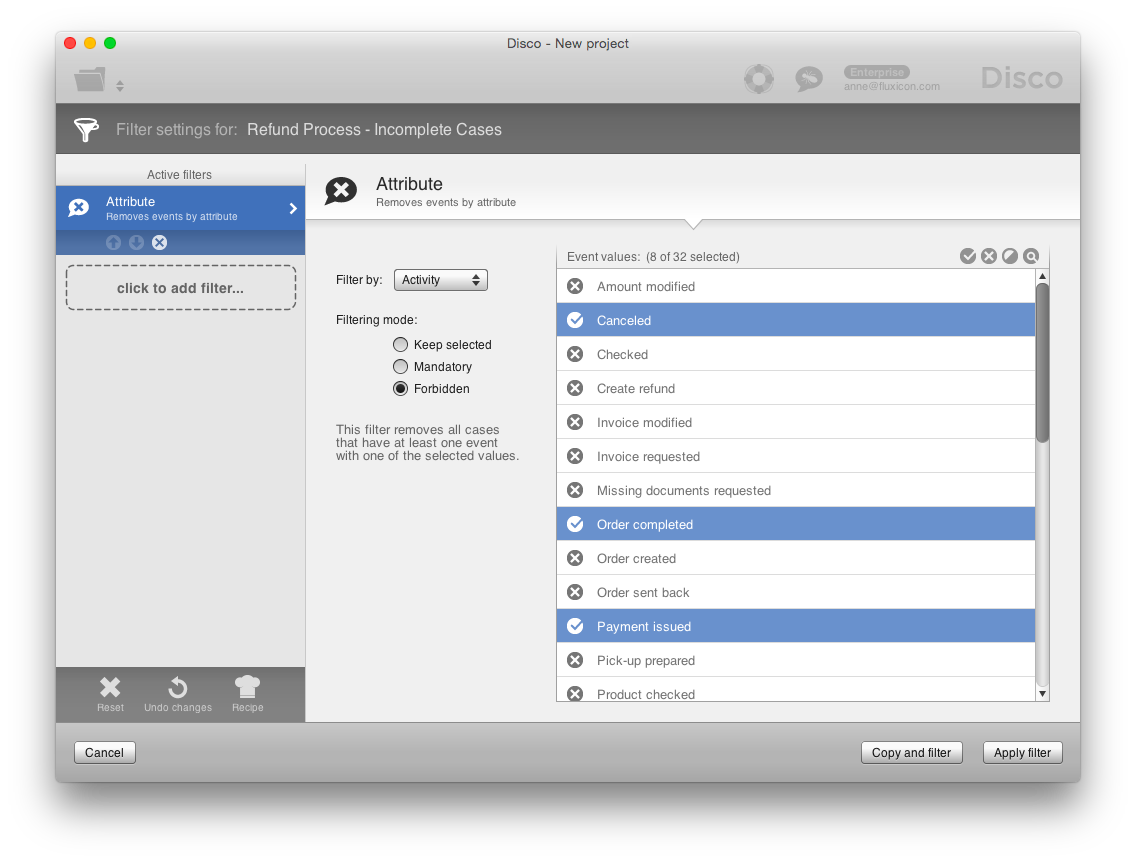
The difference between using the Attribute filter and using the Endpoints filter is that with the Forbidden mode of the Attribute filter we do not care about what exactly the last step in the process was. Instead, we want to base our incompleteness evaluation on the fact that a specific activity has not (yet) occurred. Read The Different Meanings of “Finished” to learn more about the differences between these definitions for complete cases.
For the refund process, we use an Attribute filter in Forbidden mode, in which we select the milestone activities that indicate a completion, a cancellation, a payment, or a rejection of the refund request. This removes all cases that have reached one of these milestones somewhere in the process. In addition, we combine this Attribute filter with an Endpoints filter that removes all refund requests for which we are currently waiting for the customer in the ‘Missing documents requested’ activity (see screenshot below).
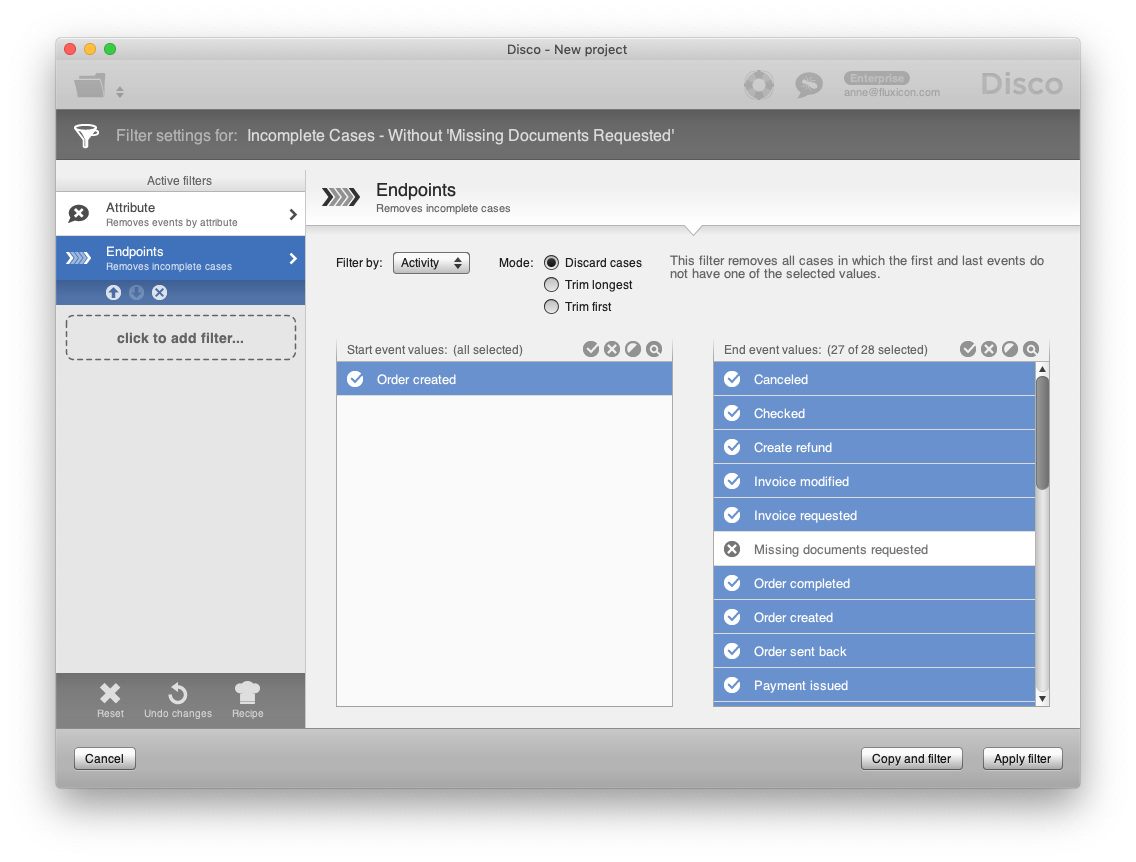
2. Export the filtered data set as a CSV file
The result is a process view that contains only those cases that are still open. As we can see, ca. 36% of the cases are incomplete in this data set (see screenshot below).
In this view, you can already see what the last activities were for all these open cases: The dashed lines leading to the endpoint indicate how many cases performed that particular activity as the last step in the process so far. For example, we can see that 20 times the activity Invoice modified was the very last step that was performed.
However, what you cannot see here is for how long they have already been waiting in this state. The problem is that when you measure the case duration in process mining, then you always look at the time between the very first and the very last event in each case, irrespective of how long ago that “last event” was performed.
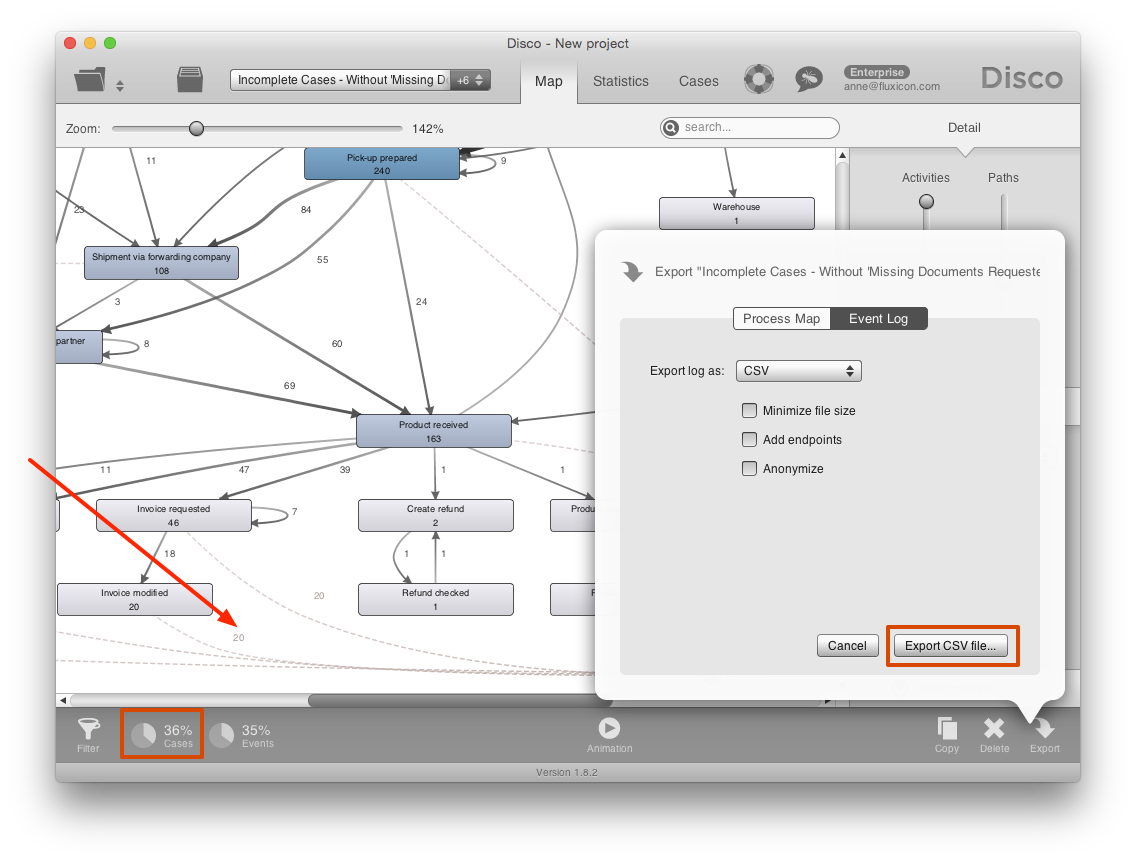
To find out how long these open cases have been idle after the last step (and for how long they have been open in total), we are going to use a trick and simply add a Today timestamp to the data. To do that, first export the incomplete cases data set using the Export CSV file button (see lower right corner in screenshot above).
3. Export the list of cases as a CSV file
We will need to add this artificial Today timestamp to the end of each of the open cases. To quickly get a list of the case IDs, switch to the Statistics tab, right-click somewhere in the Cases overview table and choose the Export to CSV option (see screenshot below).
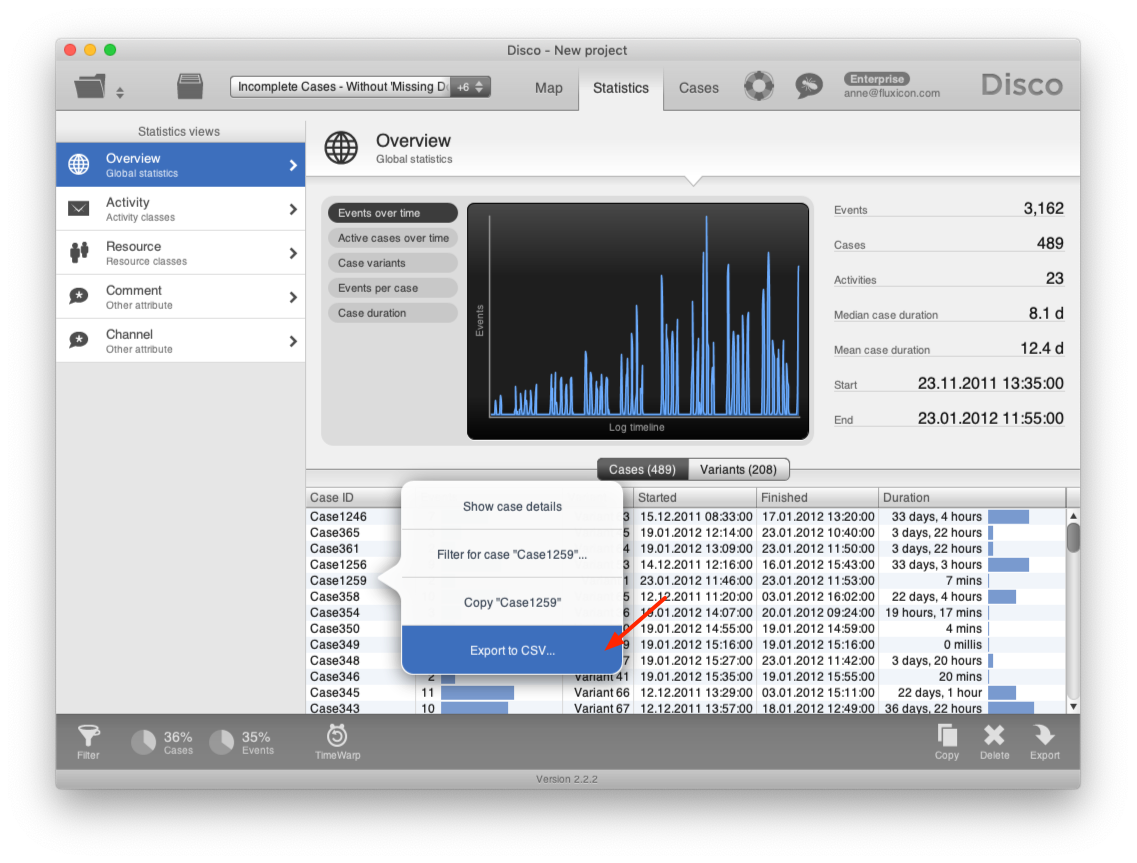
This will export a list of all open cases in a CSV file, one row per case.
4. Copy the Case IDs from the exported list of cases
Now, open the list of Case IDs that you just exported in Excel and select and copy the case IDs in the Case ID column to the clipboard (see screenshot below).
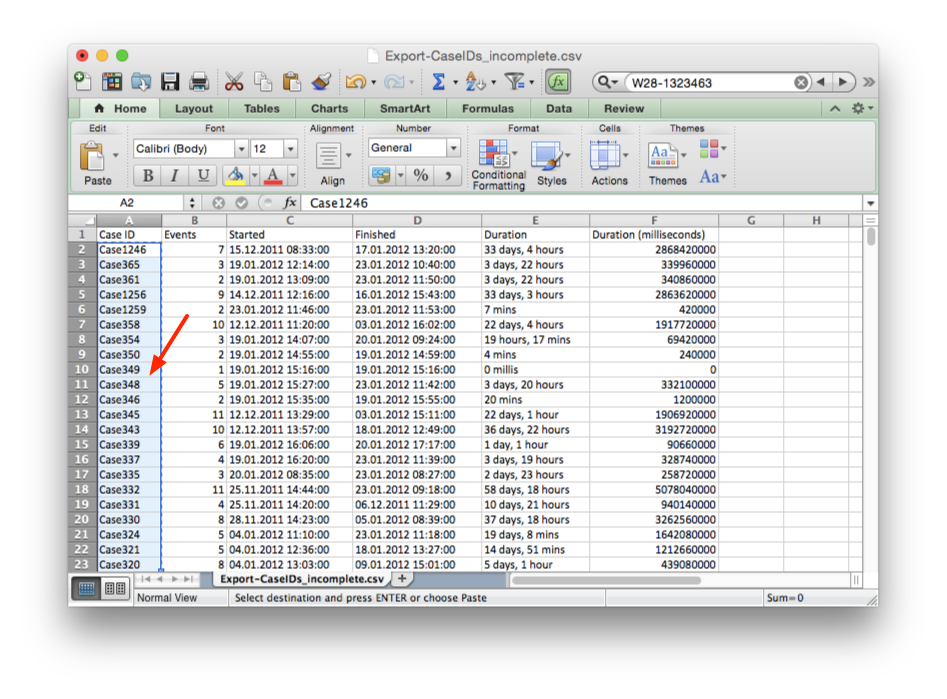
5. Append the Case IDs and add ‘Today’ timestamp
Paste the case IDs from the clipboard below the last row in the exported data file from Step 2 (see screenshot below).
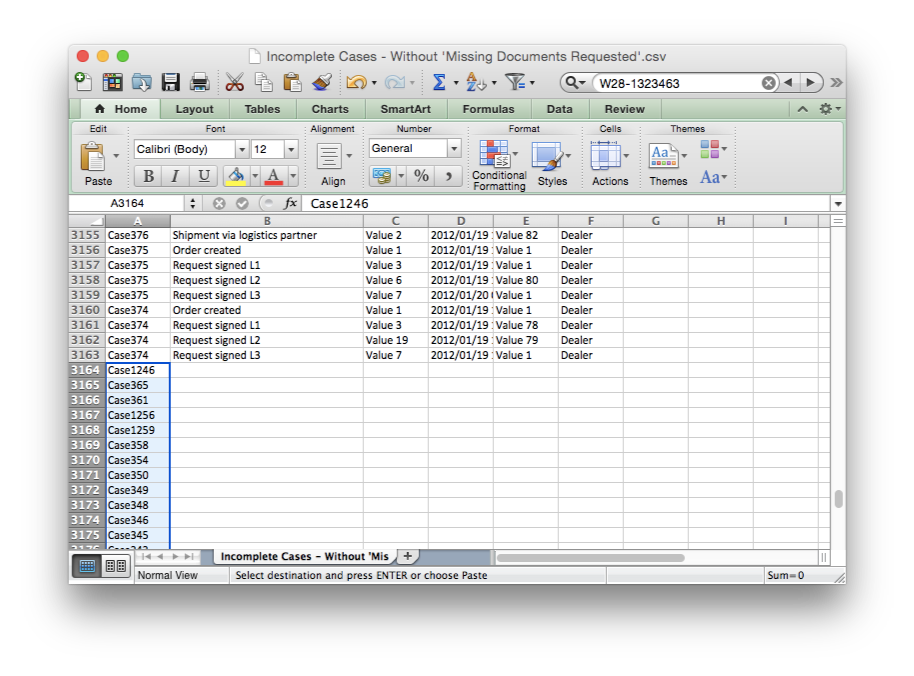
Then, type the activity name Today in the activity column for the first newly added row. Furthermore, add a Today-timestamp to the timestamp column (see screenshot below). Make sure that you use exactly the same date and time pattern format as the other timestamps in your data set.
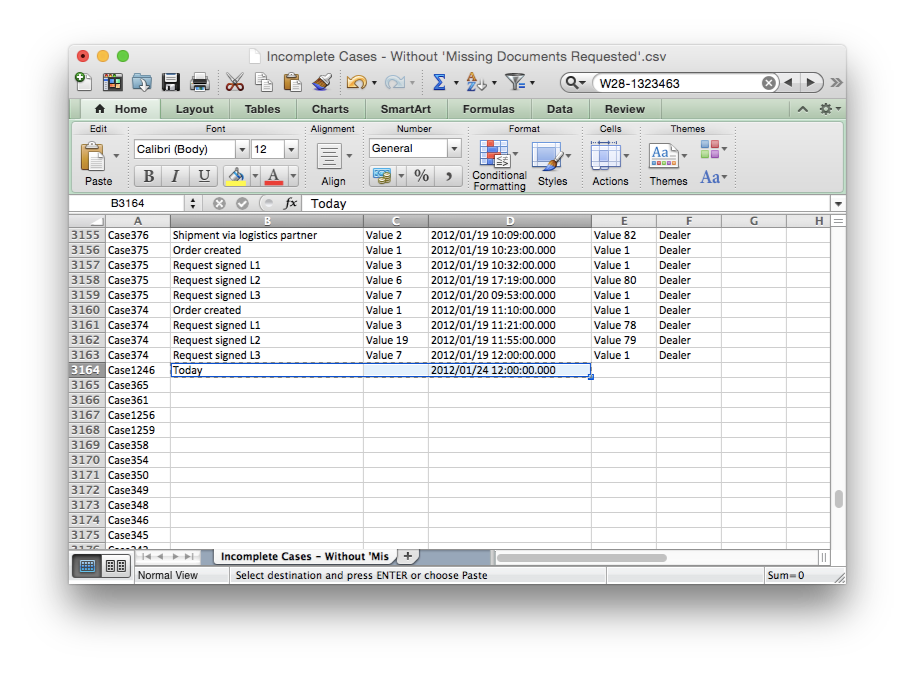
Which Today-timestamp should you use? If you have extracted your data set fairly recently (and you would assume that most cases that appear to be open in the data set are still open now), you can actually simply use your current date. Otherwise, look up the latest timestamp of the whole data set via the End timestamp in the overview statistics and use that date and timestamp to be precise. For example, 24 January 2012 was the last timestamp in the customer refund process.
Finally, copy the Today-activity name and the timestamp cells and copy them to the remaining newly added rows (see screenshot below).

6. Re-import the data to analyze open cases
If you now save your file and import it again into Disco, you will see that a new Today activity has appeared at the very end of the process (see screenshot below).
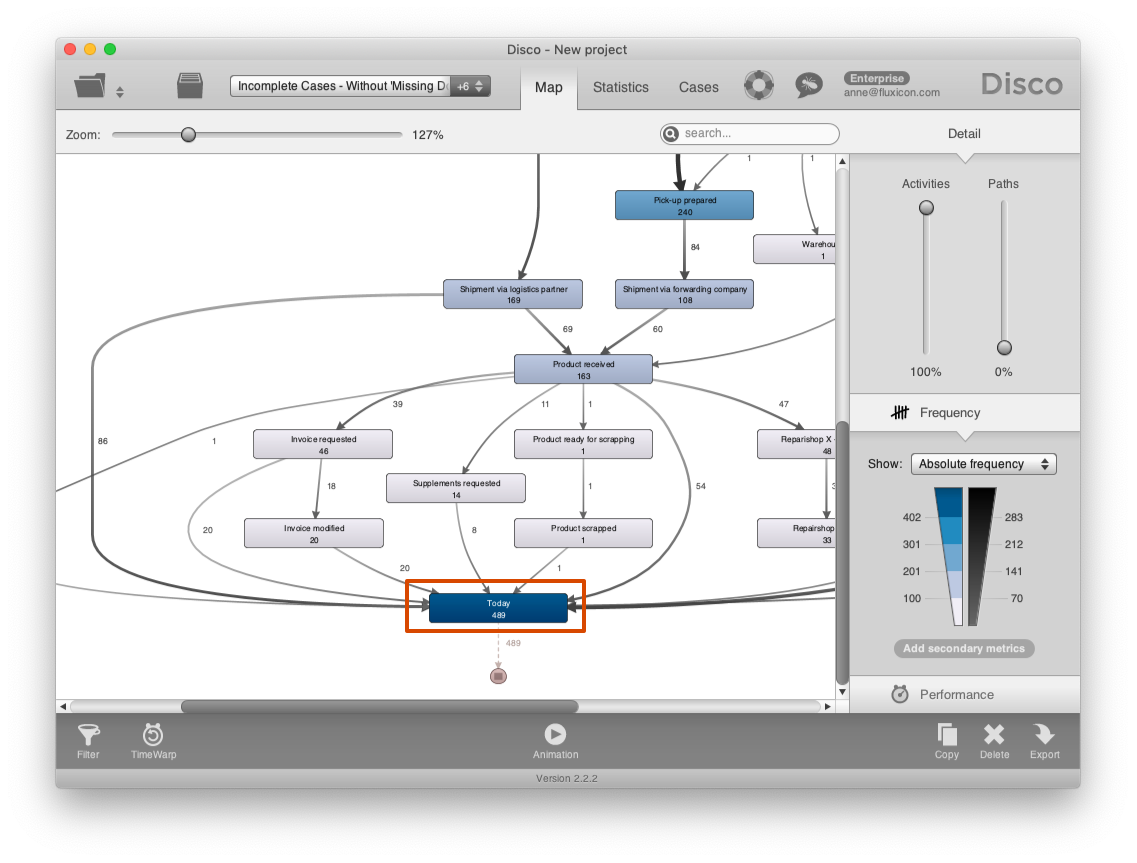
The main difference, however, will be in the performance analysis.
For example, if you switch to a combination of total and mean duration1 in the performance view of the process map (see screenshot below), then you will see that one of the major places in the process where cases are stuck is after the Shipment via logistics partner activity. On average, open cases have been inactive in this place for more than 13 days.
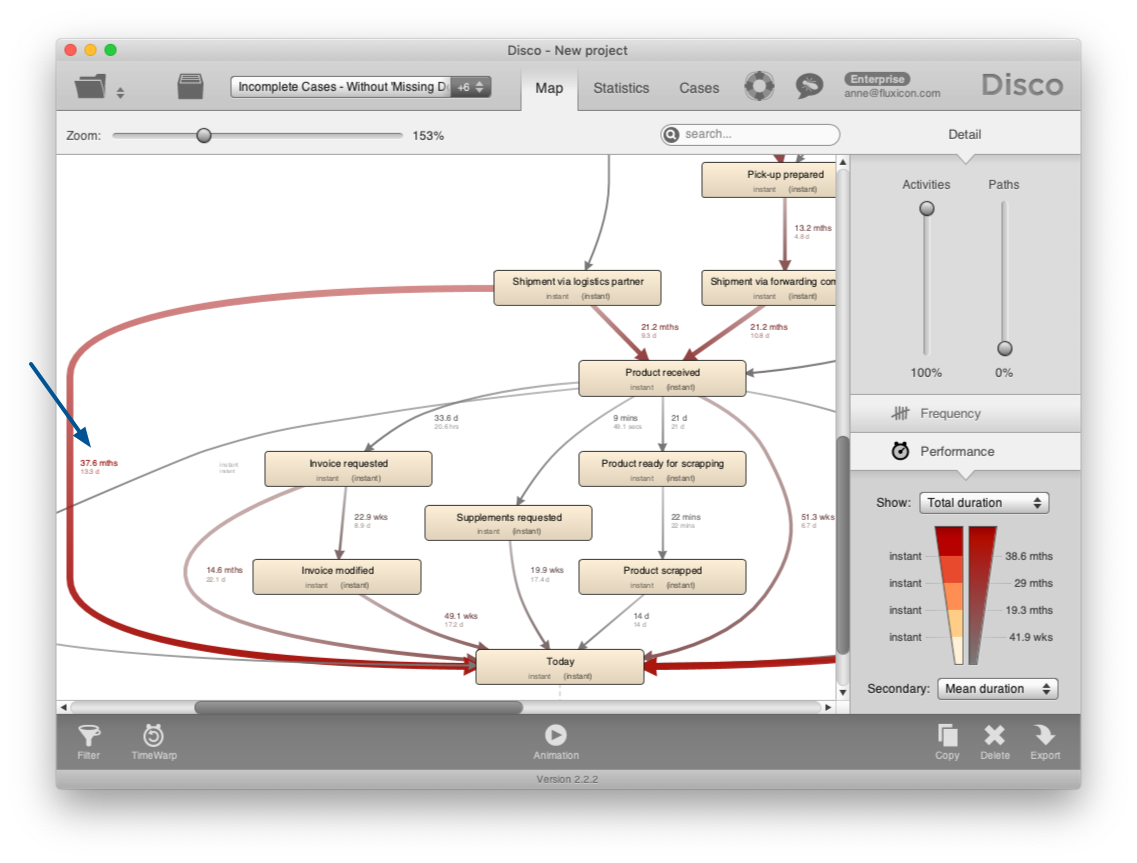
Another example is the case duration statistics, which now reflect the accurate time that these incomplete cases have actually been open so far (see screenshot below). For example, the average time that incomplete cases have been open in this data set is 24.9 days.

-
Read our article on How to perform a bottleneck analysis with process mining to learn why this combination can be useful for identifying the big impact areas for delays in your process. ↩︎

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.